The Homelike
Recently Homelike, a startup I worked at for 3 years, closed its operations. Even though I left about a year ago, I am still very grateful for having had the opportunity to play a role in the data team at Homelike. The years I spent working for Homelike were by a large margin my most prolific years.
Fig 1: Closing notice on the homelike website, as of April 2025.
I spent some time reflecting on what factors allowed for my unexpected outburst of productivity. In the first part I will outline and break down these factors. In the second I will structure in more general terms, what I learned is the role of a mature data team at a startup.
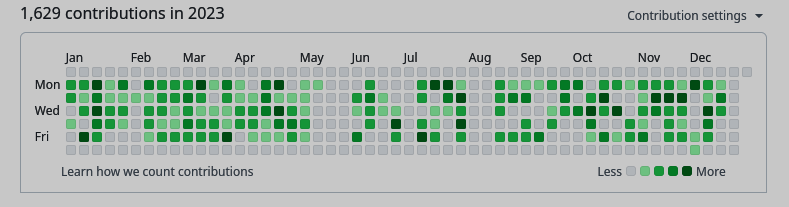
Fig 2: Github contributions for 2023. Over roughly 3 years I had accumulated thousands of contributions, and changed millions of lines of code.
Part 1: An Environment That Promotes Productivity
The Tech Was Already There
When I arrived at Homelike, I was happy to find the source code was developed using Python libraries that I had used for over 5 years. The infra was deployed to a cloud service provider I knew, and they had the same IaT framework I had been using professionally for 2 years prior to joining. All the pieces of the puzzle were already there, in place, I just had to care for and improve them.
Kind of a sidebar, but the “puzzle pieces” were very broken. The person who had originally written the software wasn’t a great software engineer. They had in their blog the Facebook saying “moving fast and breaking things” or something of the sort. I really disagree with this wording, as it leads to everything being completely broken.
The Cross-Functional Team Had Overlaps
As it is the norm in startup data teams, each person has at least one different role. What unfortunately happens often is that people in data teams isolate themselves and end up working alone on projects, and the morale goes down.
At Homelike things were different: we had a designated person for the CRM tool, a person for the Marketing tool, a person for the DWH, and the Data Engineer (me). My work had enough overlaps with each of the other roles, that my work never went unchecked, and the feedback I received from all sides was empowering and motivating. Also, by sitting at the center of the data table, I had little interaction with their respective stakeholders, which shielded me. It was a win-win situation: they didn’t have to worry about the data implementation, and I didn’t have to worry about the business.
The Leadership Allowed For Trust To Be Earned
After several months of hard work, having fixed most things and getting all pipelines green, I could feel I had the CTO’s trust in the decisions I wanted to make. I remember I had a list of some 30 red flags I had found throughout the source code, and my mind was set on one goal: I was going to take responsibility for creating the working environment that I wanted to work in.
Having my manager trust in the decisions I was making, and giving me a green light to improve things made all the difference to me. Yes, it meant that some features would take weeks to ship instead of days, but the tradeoff was unparalleled stability, and the flexibility that allowed future changes to be made swiftly. The patience that leadership demonstrated in understanding this tradeoff was phenomenal.
Strong Drive For New Features, Not Innovation
This speaks more to the culture inside Homelike (driven by the CTO), but there was a strong push for constantly developing and A/B testing new features. I mean it, the amount of things the product team was testing was mind-blowing. For the data team, this meant a constant inflow of work, since new data had to be collected, measured, and compared.
At no point did we switch to different software or tech stack, we just improved what we had. Under the hood, I was of course making huge improvements in the tech stack: newer versions of the language, newer of the libraries, cheaper cloud infra, faster CI, more stable deployments, more tests, etc. However, the foundation and the tools were always the same. There were no learning curves after onboarding.
Part 2: Data Inside A Product Startup
I wanted to explore in more general terms (not related to Homelike) what I learned was the responsibility of a data team in a product startup. What are some of the things that need to be taken care of, for the company to be successful. I believe that Data inside a startup stands on five pillars: Sales, Marketing, Finance, Product, and Data Tech itself.
Sales
Startups are not expected to develop every single piece of software they need, and chances are your sales team is used to a specific CRM tool anyway. Data from sales must flow in real-time to the data warehouse, and catering for this stream of data is a key responsibility of the data team. Sales in a startup can mean several things, so let’s break it down.
First, there is pre-sales versus post-sales. Pre-sales involves all the selling activities that take place before someone becomes a customer. Maybe it’s emails, cold calls, LinkedIn messages, etc. All of this activity should be able to be tracked and measured. Post-sales is the part of sales that happens after someone has already become a customer, and it may involve customer support or even up-selling strategies.
Secondly, there is the difference between selling supply and demand. Of course, not all companies connect suppliers to consumers, but most companies need to deal with suppliers and customers. So some part of your sales team is going to direct their attention towards your suppliers, to guarantee a steady inflow of whatever it is you’re selling. The rest of them will focus on finding the demand: the entities that may ultimately become your clients.
Marketing
Marketing is a different kind of activity to sales, that focuses on advertising your product on ad platforms, and growing your company’s brand (organically or not). All the marketing data needs to be find its way into your DWH, and this is the responsibility of the data engineers to figure out.
A very important use of this data is to calculate an attribution model: a calculation that determines what percentage of a specific revenue stream should be attributed to each marketing initiative. This in turn allows the marketing wizards to compare how much revenue each ad strategy is bringing (versus their cost), and optimize them accordingly. Of course marketing data is also used for analyzing which strategies are bringing in your desired metric (e.g., new users, revenue, monthly active users, etc.) or not.
Finance
Finance data involves all the monetary transactions that take place when a customer buys, sells, subscribes, or returns a product. Maybe this takes place in a payment gateway that you use, a point-of-sales tool, or even it takes place directly in your company’s bank account. Whatever your operating mode, the data team must make sure that financial data makes its way into the DWH. A very important task for a data team is to be able to match an invoice to a transaction so that no invoice or return goes unpaid.
Product
The heart of a startup is its product or service. Data about your products, and how users are interacting with them needs to be registered in your DWH. Accurate and timely product data allows for such much insight, that it is vital for the business. Here are some examples of things that a data team could develop to better understand its customers:
- supply availability (stock forecasting)
- competitive price modeling
- customer lifecycle analyses (churn models, survival curves, customer lifetime value)
- product lifecycle (product conversion rate, up-sell propensity, renew propensity)
- user-interaction data (search conversion rate, A/B tests)
Data Tech
I wanted to highlight some of the work-streams and platforms that would be under the data team’s umbrella. This is not an exhaustive list, but the ones that I personally care the most about.
First and foremost the data storage: there is the maintenance, development, and support for the Data Warehouse, the Database, and their backups.
Secondly there are the data transfers. A data team needs to be able to deploy and maintain ETL pipelines (batch jobs), streaming pipelines (near-real time), and all analytics aggregations (think dbt models).
Finally, all things that are important around data: scalability, stability, comprehensive monitoring, data transparency within the organization, self-service analytics, data privacy (especially around PII and right-to-be-forgotten), and of course keeping cloud costs down.
Epilogue: Notes on VC-backed enterprises
Not directly connected to Homelike, but there’s something to be said about companies that are operating at a loss, backed by venture capitalists. Even if they have good products and a good team, you know they are burning money in unsustainable growth. I think it is a wise decision to not buy from these companies, and to not work for them. Even if the money is good. Even if you believe the mission. If you see your company is spending money in the wrong things, might be time to find a new gig.